博物馆领域人工智能的应用研究
来源:
《自然科学博物馆研究》
作者:
马玉静 孟睿伟 徐浩 管欣鑫
发布时间:
2025-09-17 08:56
【摘要】随着数字技术的迭代演进,互联网、大数据、人工智能和实体经济的深度融合,产业数字化对数字经济增长的主引擎作用更加凸显,文化数字化拥有非常广阔的发展空间。人工智能作为引领新一轮科技产业革命的战略性技术,正在引发经济、社会、文化等领域的变革和重塑。博物馆作为文化遗产保护和传承的公共文化机构,在“数据、算法、算力”新一代数智技术驱动下,将人工智能技术应用于博物馆收藏、保护、展陈、传播等多个方面,成为博物馆文化遗产数据资源建设与活化利用的新型生产力,引领文博领域数智化发展新方向。
【关键词】博物馆;人工智能;深度学习;多模态检索;大语言模型
党的二十大报告指出要加快建设网络强国、数字中国。人工智能作为引领新一轮科技产业革命的战略性技术和新质生产力的重要驱动力,正在引发经济、社会、文化等领域的变革和重塑。2022年末,以OpenAI公司ChatGPT为代表的生成式人工智能技术应用火遍全球。其强大的内容生成及多轮对话能力,引发全球新一轮人工智能创新热潮。国内外随即掀起了一场大模型浪潮,Gemini、文心一言、Copilot、SORA等各种大模型如雨后春笋般涌现。到2024年底,国产开源大模型Deepseek的横空出世颠覆了人类的认知。这些模型和应用可以生成流畅和连贯的文本、逼真和多样的图像、原创和风格化的音乐等,展示了人工智能的高超创造力和丰富想象力。
2022年5月,中共中央办公厅、国务院办公厅印发《关于推进国家文化数字化战略的意见》,明确国家文化大数据体系发展目标,实现中华文化全景呈现,中华文化数字化成果全民共享。2023年,中共中央、国务院印发《数字中国建设整体布局规划》,从党和国家事业发展全局的战略高度做出了全面部署。数字经济规模由2012年的11.2万亿元增长至2023年的53.9万亿元,占GDP比重的42.8%,成为国民经济的关键支撑和重要动力,其主要由产业数字化和数字产业化构成。产业数字化即传统产业由于应用数字技术所带来的生产数量和生产效率提升,其新增产出构成数字经济的重要组成部分。2023年产业数字化规模为43.8万亿元,占数字经济的比重为81.2%。由此可见,随着数字技术的迭代演进,互联网、大数据、人工智能和实体经济的深度融合,产业数字化对数字经济增长的主引擎作用更加凸显,文化数字化拥有非常广阔的发展空间。
人工智能的核心是“数据+算法+算力”。数据是核心生产要素,文化大数据是真正意义上的生产要素,来源于中华民族积淀了数千年的文化资源,具有深刻的文化内涵,是真正意义上的高质量数据。文化大数据作为新型生产力,与互联网数据相比,具有成体系、质量高、价值大的特征。随着万物互联、智能时代的到来,数据的爆发式增长,对算力的要求日益提高,同时伴随着由摩尔定律支撑的中央处理器(CPU)、图形处理器(GPU)、云计算等基础运算能力的不断提升,人工智能(AI)算法通过大量数据样本的训练和算法参数调整,产生智能的预测结果。因此,在“数据、算法、算力”新一代数智技术驱动下,人工智能正成为博物馆领域文化遗产数据资源建设与活化利用的新型生产力。
一、人工智能技术发展及现状
(一)人工智能诞生及发展
“人工智能”可以追溯到20世纪50年代。美国计算机科学家约翰·麦卡锡及其同事在1956年达特茅斯会议上提出,其后经历了1956-1976年以基于符号逻辑推理证明为主的第一阶段,1977-2006年以基于人工规则的专家系统和统计机器学习为主的第二阶段,以及2007年至今以大数据驱动的深度神经网络为主的第三阶段,自此人工智能进入第三波热潮。人工智能按其模型来划分,可以分为决策式人工智能和生成式人工智能,两者共同特征是都离不开用大量数据来训练模型。
(二)人工智能技术
人工智能是一门交叉性学科,近年来的研究主要集中在深度学习、自然语言处理、计算机视觉等技术领域。此外,随着人工智能技术不断发展成熟,数据可视化、机器人、生物识别、知识图谱等也成为人工智能技术的重要组成部分。图1直观展示了人工智能技术的交叉特性。
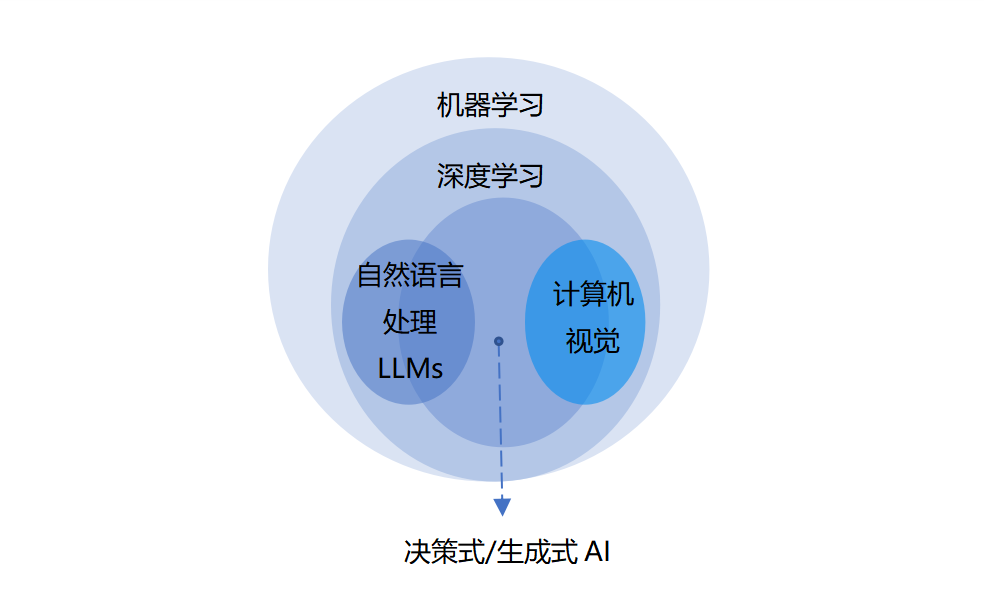
图1 人工智能技术的交叉特性
1.深度学习
深度学习起源于人工神经网络。深度学习的实现机制,是由训练者提供某个复杂领域里的大量样本,让机器用特定函数来拟合这些样本,实现样本的模式构建和结构刻画,从而建立起模型用以处理和训练新样本。它最大优势在于让机器自身从海量的数据中习得规律,从而对新的数据做出智能识别或者预测,是机器学习的子集。
2.自然语言处理
大语言模型(LLMs)是一种强大的自然语言处理模型,使用深度学习技术来理解和生成自然语言文本,其本质是一种参数量巨大的神经网络。训练后的大语言模型通过分析文本结构、语法和语义等特征,分类、标注实体命名、语音识别等实现了对自然语言文本的深度理解,这使得它在文本生成、翻译、问答等多个人机交互方面都具有巨大的应用价值。
3.计算机视觉
计算机视觉使用图像处理、深度学习等技术,使计算机能够理解和解释图像、视频。它综合了图像处理、机器学习、模式识别和深度学习等多项技术。特别是随着深度学习技术的发展,卷积神经网络等能够自动提炼图像中复杂特征的深度神经网络,已成为该领域的核心工具。
二、博物馆人工智能技术的应用
随着新一代信息技术的发展,博物馆经历了从数字化到数据化,再到数智化的发展过程。人工智能技术和应用往往具有交叉性质,并处于不断发展和演进的过程中。当前阶段,人工智能技术的运用能帮助博物馆标注、识别、分类藏品,使用户能在海量藏品数据中实现精准查找;通过计算机视觉、文物图像特征提取,可以辅助专家评估文物的损坏程度,虚拟文物修复过程;利用深度学习技术、卷积神经网络算法等,可识别甲骨文字,实现甲骨缀合;基于数据可视化的展览数据创新展示,使观众获得更具创新意义的艺术启发;利用大语言模型和知识图谱、虚拟现实和增强现实等技术的智慧导览,根据观众的历史行为和偏好推荐感兴趣的展品或展览,为观众提供交互式和沉浸式体验,引领新时代文博领域向数智化发展。
(一)基于多模态检索增强的藏品信息管理
藏品信息管理是博物馆的基础工作,藏品名称、年代、质地往往是识别和查找藏品信息的有效途径。由于藏品名称一般按照年代、特征、形制等综合起来命名,在面对数百万件藏品信息进行检索查找时,常常需要专业领域知识才能在检索时做到有的放矢。同时,藏品著录元数据多为结构化数据且孤立存在,藏品数据知识单元粒度不够细致,相互之间关联关系不足,且藏品数据检索查找多采用关键字匹配、全文检索等基于文本数据的方式,这种方式在满足用户精准信息查找需求方面存在明显不足,导致业务人员在使用过程中,经常会出现明明数据库里有,却查找不到,或者“查非所需”的情况。
多模态数据检索是一种涉及文本、图像等多种媒体模态的信息检索方法。为实现搜索的精准高效,首先要进行数据处理:对于文本数据,使用自然语言处理技术来提取关键词、实体、主题等信息,构建文本的特征向量;对于图像数据,利用计算机视觉技术来提取图像的特征,包括颜色直方图、纹理特征、形状特征等,从而构建图像的特征向量。其次,对文本和图像的特征向量通过向量拼接、加权求和等方式进行特征融合,融合后的特征向量用于计算相似度或进行机器学习算法的训练。然后,利用卷积神经网络的深度学习算法来计算文本和图像数据之间的相似度,便于找到与查询数据最相似的文本和图像数据。最后,利用自然语言处理和计算机视觉技术,进行语义理解,以更好地理解文本和图像数据之间的关联。
因文物编目信息和图像特征的独特性,目前通用大模型很难发挥有效作用。多模态数据检索原理机制基于深度学习和大语言模型技术,通过对文本、图像语义的深度理解和智能推荐机制,实现搜索的精准高效。全球最有影响力的数字文化平台Google Arts & Culture,一直通过深度学习来分析历史上的图片、艺术品的视觉相似度,同时运用t-SNE数据可视化算法对其作者、主题、色彩、风格、构图、材质等方面进行分类,用户按任意分类都可以检索出优质内容。故宫博物院“数字文物库”通过构建主题词表、知识图谱等方式,在不同层级上下文之间实现知识的相互关联,一方面便于用户的检索查找,另一方面为检索到的文物提供相关性推荐,在此基础上的大模型应用,能帮助用户更加充分、深度和高效地利用文物资源。
(二)基于计算机视觉的文物虚拟修复
文物发掘出土时会有破碎残损的情况,采用传统手工方法复原,不仅操作难度大,而且是不可逆的,一旦操作失误会造成二次损伤。人工智能技术的迅猛发展,尤其是深度学习技术具有学习、分析、总结的能力,能够对数字化的文物图像断面进行特征提取、分析,利用碎片拼接与虚拟文物修复方法,为破损文物的复原提供鲁邦的匹配算法及快速精确的拼接技术,可以解决人工复原中工作量大、周期长及文物二次损伤等问题。
基于计算机视觉的文物虚拟修复,首先利用三维扫描、摄影测量等技术手段,对文物进行高精度的数字化采集,获取文物的三维模型、纹理信息等数据。然后,利用计算机视觉技术对采集到的文物图像进行分析和处理,包括图像增强、去噪、分割、特征提取等步骤,以提取出文物的形状、纹理、颜色等信息。最后,利用深度学习算法对文物进行虚拟修复,包括碎片的拼接、矫正、补全、复原等步骤,以恢复文物的原始形态和外观。
2023年,三星堆博物馆、四川省文物考古研究院和腾讯合作,开展新出土文物的虚拟修复,通过计算机视觉和对称性检测等算法,实现了出土文物碎片的特征提取、虚拟拼接、复原矫正等,顺利完成“铜兽驮跪坐人顶尊铜像”的模拟拼接,为三星堆文物的保护和修复探索了科技化的路径和方法。
(三)基于深度学习技术的古文字识别
古文字是珍贵的人类文化遗产,承载着丰富的历史和文化信息。但因饱经岁月洗礼,存在严重的退化、模糊等问题。基于深度学习的古文字识别主要依赖于计算机视觉、卷积神经网络等深度学习模型。首先,需要对古文字图像进行预处理,包括灰度化、二值化、图像增强等操作,以提高图像的质量和特征提取的准确性;其次,利用卷积神经网络中的卷积层、池化层等结构,提取古文字图像的局部特征和全局特征;最后将提取的特征向量输入到softmax、支持向量机等分类器中,通过训练模型进行识别和分类。
基于计算机视觉技术、卷积神经网络等算法,一方面可以做甲骨缀合,主要是综合利用甲骨的文字和图像信息,将两片及以上的甲骨碎片拼接起来,变为完整或较为完整的材料。另一方面是甲骨文字释读,主要是通过人工智能技术,检测和识别古文字字符,对未识读的甲骨文进行破译。华中科技大学白翔教授带领团队的合作研究成果“利用扩散模型破译甲骨文”,该模型利用扩散模型模拟汉字演变过程,将甲骨文文字图像转化为现代汉字图像,通过产生未破译甲骨文的现代汉字来反推其含义,从而辅助破译甲骨文。
2019年,安阳师范学院甲骨文信息处理教育部重点实验室推出了第一款免费甲骨文大数据平台“殷契文渊”,通过采集高清的甲骨图片信息,然后把甲骨实物文字和标准文字进行关联,提供了各类人工智能技术研究所用的专用公开数据集及各类信息资源整合服务,供专家学者查找。
2024年世界人工智能大会上,“数字甲骨共创中心”将全球最大的甲骨文多模态数据集开源,该数据集包含一万片甲骨的拓片、摹本,以及甲骨单字对应位置、对应字头、对应隶定字以及辞例分组、释读顺序等数据。基于该数据集,研究人员可开发甲骨文检测、识别、摹本生成、字形匹配以及释读等方向的智能算法,助推甲骨文研究加速数字化和智能化。国家博物馆利用此数据集作为基准数据集,采集馆藏甲骨文藏品影像,训练识别模型;建立团队协同的图像标注平台,对甲骨文图像进行标注,利用人工智能技术,检测和识别古文字字符。用户可以通过古文字知识服务平台进行现代汉字关键词检索,查询相应的古文字和馆藏文物数据,还可以上传古文字文物图片,识别图片上的古文字并给出相应的现代汉字,平台为古文字研究提供了强有力的工具。
(四)基于数据可视化的创新展示
艺术作为凝结了人类知识、情感和思想的精神领域,曾被视为科技难以逾越的高地。而如今在“文化+科技”交叉融合的趋势下,当代艺术的观念也发生了根本变化。许多博物馆、美术馆开展了跨学科领域的合作,将人工智能技术应用于馆藏梳理、作品展示中。2022年底,纽约现代艺术博物馆(The Museum of Modern Art,简称MoMA)展示了特别展览项目“无人监控”(Unsupervised,见图2),呈现艺术家雷菲克·阿纳多尔利用人工智能演绎的馆藏艺术、设计和摄影作品,经过分析、数字化、输入算法后,在24英尺高的LED墙中数据可视化呈现出来,整个大厅里弥漫着色彩与三维动画,被认为是机器的幻觉和梦境。

图2 纽约现代艺术博物馆特别展览项目“无人监控”
雷菲克·阿纳多尔通过训练智能学习模型,在读取了138151张图像的数据之后,实行自主无监督的学习,重新诠释MoMA的馆藏,以人工智能视角想象现代艺术的历史轨迹,就可能存在的过往以及未来故事展开联想,同时结合MoMA大厅的环境数据,包括光线、运动、声音和天气的变化,来影响不断变化的图像和声音。展览带给观众的是一场关于技术、创造力和现代艺术的沉思。这种方式让观众可以用一种新的视角回顾过去,跳出原有的思维模式,获得更多、更具创新意义的艺术启发。
此外,利用生成式人工智能强大的创作能力,策展人可以从知识库中自动将关联数据生成不同主题并进行推送,形成简单的策展文案和展品目录。并根据观众感兴趣的主题,发挥自主原创能力,为观众提供创作的素材和众包平台,开展策展人、专家、公众等多种形式的联合策展。运用机器学习的内容生成具有决策功能的人工智能工具,在统筹分析展览目的、资源的基础上,通过对藏品、人物、历史等数据的分析和挖掘生成展览大纲。2022年,布加勒斯特双年展的策展人,就是一个以钢铁侠管家命名的人工智能策展人“AI Jarvis”,Jarvis利用新型生成对抗网络(GAN),通过分析和挖掘艺术学院、画廊和博物馆等数据库中的数据区生成展览主题,并挑选出符合此主题的参展作品。
(五)基于大语言模型的智慧导览
得益于自然语言处理、生成对抗网络(GAN)等深度学习算法的快速发展,大语言模型在精准内容生成和增强搜索的深度方面展现出显著的核心能力。通过将大语言模型进行本地化部署,结合涵盖博物馆展览咨询、导览路线、展品解读、观众画像等本地数据库,持续收集观众问题,逐步建立起观众交互问答知识库。主要体现在以下几个方面:一是基于观众需求的内容生成。博物馆通过对观众参观前、参观中、参观后等数据采集治理、标签分类设定、数据挖掘分析等,为观众构建画像。根据观众的喜好,生成高度符合观众需求的内容。二是智能推荐机制。基于用户输入的关键字和语义信息,推荐与用户需求高度相关的内容,从而提高搜索效率和用户体验。三是知识图谱的应用。大语言模型使得构建藏品本体相关的知识体系高效易行。通过对藏品多源异构数据的全方位收集、细粒度标注、多维度关联等,构建藏品知识图谱,对生成内容进行语义标注和分类,从而增强内容生成和搜索的精确性、丰富性。
基于大语言模型的智慧导览使观众可以跟博物馆交互对话:博物馆借助知识图谱对文物信息和知识的归纳整合,以文字感知、需求理解的方式开展智能化的文物讲解、交互对话、推理决策等;开发聊天机器人或虚拟助手,为参观者提供个性化的导览服务,解答观众的问题,并提供展品的详细信息;用于实时翻译,帮助不同语言背景的参观者更好地理解展品说明和文化背景,对于国际文化传播的价值不言而喻;辅助内容生成创作,如自动生成展览介绍文本或宣传材料等。
2022年,国家博物馆推出数智人“艾雯雯”,不仅担任实体展览讲解,还引领观众在云端沉浸式观展。此外,结合实景拍摄,充分运用数字科技赋能文物活化,观众可以在“艾雯雯”的带领下,“突破”时空限制,与“活起来”的文物对话,在感受中华优秀传统文化中提升文化自信。此外,首都博物馆推出数智人“京慧”,依托定制化的观众服务AI大模型和首都博物馆专属知识库,拥有自然语言、自主学习、个性化交互等智慧化能力。辽宁省博物馆“辽小博”在AI智慧导览系统中,应用基于知识图谱和大模型融合微调的人工智能技术,能够实现更加精准、智能、个性化的知识问答、内容推荐和位置导航服务,为观众带来新鲜有趣、千人千面的博物馆学习体验。
三、人工智能技术应用面临的挑战
尽管人工智能为文化遗产的数字化保护和创新传播开辟了新路径,但其在博物馆领域的深度应用仍面临多维度的系统性挑战,存在文化遗产高质量的数据资源匮乏、数据安全、隐私保护等诸多风险。如何在妥善保护文物的同时,利用人工智能技术对文物进行深入研究、阐释、传播,是当代博物馆工作者面临的机遇和挑战。
(一)文化遗产数据智能治理挑战
博物馆保存有海量的文物二维、三维影像,音视频,全景漫游,历史地图等影像数据资源,以及考古报告、专业出版物等文本数据资源,还沉淀有数亿级别的观众用户数据。这些多模态数据要在人工智能时代发挥应有价值,具备理解、生成、逻辑、记忆等人工智能大模型的基础能力,意味着要做好细粒度标注,数据关联和治理,模型训练和智能体构建等。
文化遗产数据专业性强,数据治理非常复杂。构建文物知识图谱需百万级专业标注数据,标注工作需要大量的人力、物力条件,更需要领域专家的支持和帮助。如青铜器纹饰及铭文释读等标注工作需要依赖古文字专家,导致标注成本大大提高。
观众行为数据采集面临隐私保护与技术实现的双重挑战,既要突破方言识别、情感计算等技术瓶颈,又需在个性化服务与数据安全间建立平衡机制。
(二)人工智能技术快速发展与人才挑战
人工智能技术发展日新月异,在技术层面,随着大模型规模和复杂度持续攀升,如何将通用大模型应用到文化遗产专业领域,建立“通用”到“专用”的文化遗产大模型,是当前面临的主要挑战。同时,大模型发展也面临算力受限、数据短缺、模型自身性能有待提升,以及软件生态不完善等诸多挑战,极大地束缚了行业的自主发展。
在人才层面,大模型领域的快速发展导致专业人才供不应求。技术的快速发展,使其逐步演化为一种工具,因此更需要既懂业务又懂技术的跨专业人才,这也是当前博物馆人才方面的短板。
(三)意识形态安全与伦理问题挑战
人工智能技术可能导致意识形态安全和伦理问题,如应警惕大模型在文物阐释中可能产生的历史虚无主义倾向,以及存在“幻觉”、生成虚假信息等问题。生成式人工智能自出现以来,其“幻觉”问题就一直存在,这一问题虽然在过去两年有了显著提升,但纯粹利用技术手段消除生成式人工智能虚假信息问题的前景并不乐观。
博物馆是意识形态和知识传播的主要阵地,人工智能技术的应用还要结合制度约束、内容审核等人工手段,在确保正确和安全的情况下,守护好、传承好、展示好中华文明优秀成果。
(四)数字版权法律体系健全挑战
人工智能高度依赖大量的训练数据来学习和生成内容,但这些数据中可能包含了受版权保护的内容,因法律滞后等问题导致生成式内容侵权监管存在缺失。同时,博物馆文物数字资产面临确权困境,如文物三维数字化模型版权归属目前还存在法律空白等问题。
为确保生成式深度学习模型的合规性和道德性,一方面,需要建立相应的法律法规和技术标准,并加强监管和审查机制。另一方面,随着人工智能技术的不断发展,不同行业领域的数据呈现多样化和专业化的特点。博物馆不但需要跨领域的专业知识和技术支持,还需建立完善的内容审查机制,对生成的内容严格把关,确保不含有任何侵犯第三方知识产权的元素。
四、总 结
随着近年来数据的爆发式增长,计算能力的指数级提升,以及深度学习算法的发展成熟,人工智能技术取得高速发展。在记忆方面,数以百万计的文字形体总量,人脑只能记住其中很小一部分,而智能模型却可以全面覆盖,达到知识快速联结,决策更为高效的目标。多模态增强、图像识别等技术实现了文物价值的深度挖掘,如吉林大学李春桃等开展了基于深度学习技术的青铜鼎分期断代研究等。在用户交互和问答系统中,大语言模型能够基于上下文和历史数据,生成逻辑性强、信息丰富的回答,表现出较高的准确度和灵活性。知识图谱技术推动了文化遗产的活化利用,生成式人工智能在文物阐释领域展现出类专家级的叙事能力,创造了文化传播的新范式。
人工智能技术的飞速发展,为实施文化数字化战略,统筹利用文化领域取得的数字化成果不断赋能。文化遗产数据蕴含着中华民族的文化基因,是真正意义上的生产要素。当前人工智能领域通用大模型迅猛发展,如果能将文化遗产数据转化为人工智能大模型的训练语料,就可以形成具有深厚历史文化底蕴的文化行业大模型,从而推动人工智能在博物馆领域的高质量发展。另一方面,技术有时是一把双刃剑,技术不应止步于工具性创新,更需服务于更深层的文化使命。诚然,技术赋能文化的过程始终伴随着多维度的风险,人工智能在博物馆领域的高质量应用还要兼顾意识形态、技术安全等多方面因素,只有坚守正确政治方向,坚定文化自信,才能牢牢掌握人工智能时代的主导权、自主权,构建起文化安全与技术创新动态平衡的发展机制。